. regress depvar[ varlist]
which means a regression where the dependent variable is depvar, and the list of regressors is in varlist. Let's try it off:
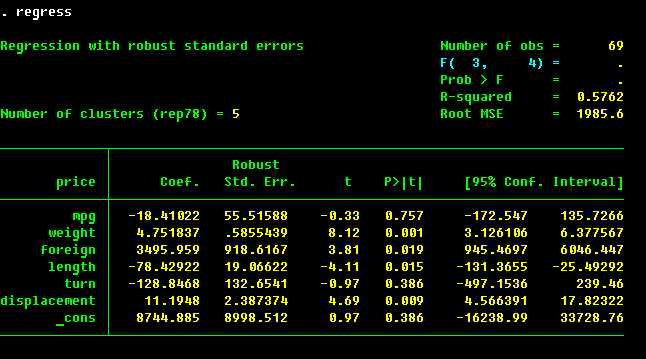
. reg pri mpg wei for
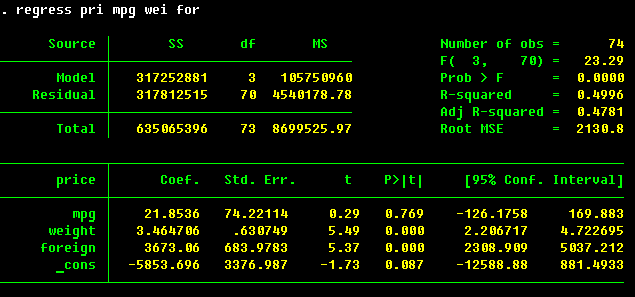
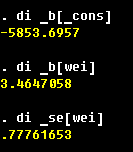
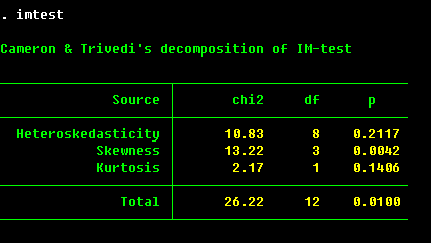
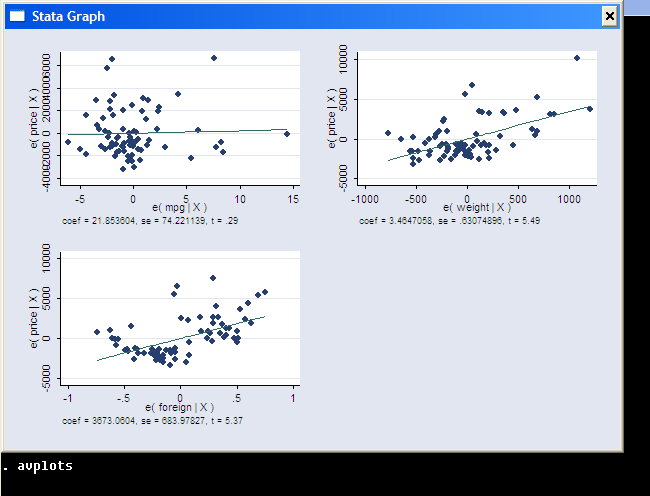
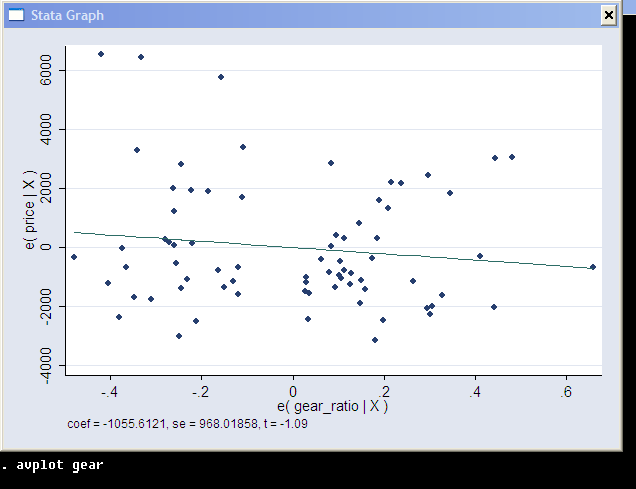
The most important information is in the lower pane of the regression output. Here we have the names of the dependent variable (price) and of the explanatory variables (mpg, weight, foreign; _cons is the constant term, or the intercept of the regression. To omit one, specify nocons option of regress. To indicate to Stata that you already have a constant term among regressors (this is helpful in some panel data regressions), specify hascons option). The next column are the estimated coefficients β = (XTX)-1XTY. The third column are the estimated standard errors, which are the square roots of the diagonal entries of the estimated covariance matrix, which in this is s2 (XTX)-1 (it is going to be different for some other models). The t statistics in the next column are the ones to test the null hypothesis of no linear relation between the explanatory and the dependent variable conditional on other explanatory variables (i.e., that respective β is equal to zero). The p-value for the test is provided in the next column. Finally, the confidence interval for the coefficient is given in the last two columns.
A little bit longer explanation of what Stata shows after regress is available at UCLA Academic Technologies Services Stata website.
From the estimation results, we can infer that weight and price are positively related,
that the foreign cars are on average more expensive by $3673, and the mileage is not
significantly related to price in this model. The R2 is reasonable at 0.50, but
not particularly high. Let us refer to this model as Model 1. We can save the estimation
results in Stata, too:
. estimates store Model1
As with most Stata commands (and as with all estimation commands), you can add
if/in qualifiers to restrict the estimation subsample:
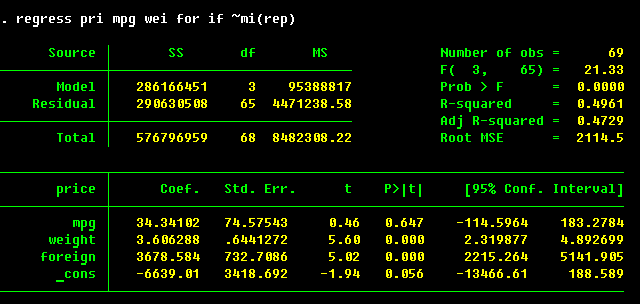
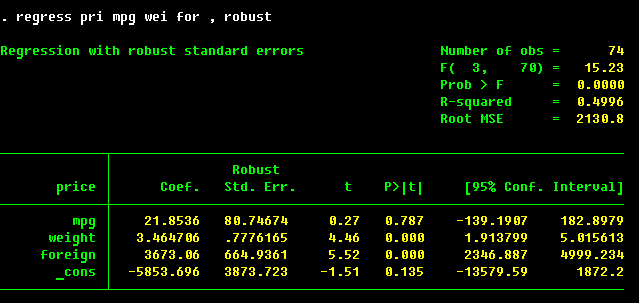
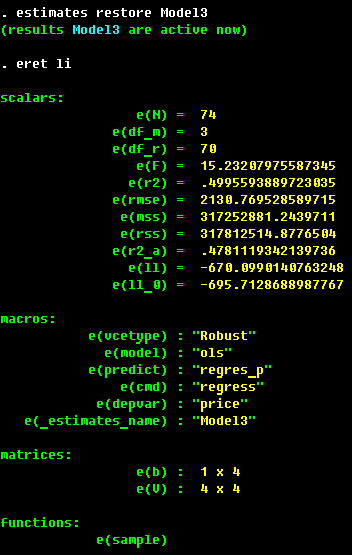
. estimates store Model3
Note that we have the same subsample as in Model 1. The point estimates
are the same, but the standard errors are slightly larger, except for foreign variable.
This increase is a typical outcome of the correction.
In general, the robust correction is available for most models estimated by maximum likelihood;
see help for _robust.
Linear regression is an example of such model if one assumes normality of residuals. The
robust correction in this case gives consistent estimates of the standard errors
if the distribution of the residuals is different from the normal with fixed parameters.
For models such as probit, the corrections is for the violations of the assumed
probability distribution (say the underlying link between Xβ and the probability of a
positive outcome is logit rather than probit).
If you have reasons to believe that some observations are grouped together by the data
generating mechanism, you can specify cluster() option to account for this effect:
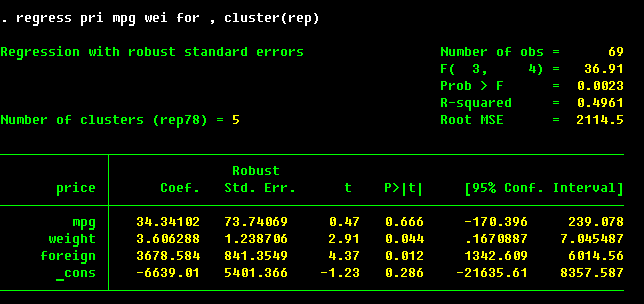
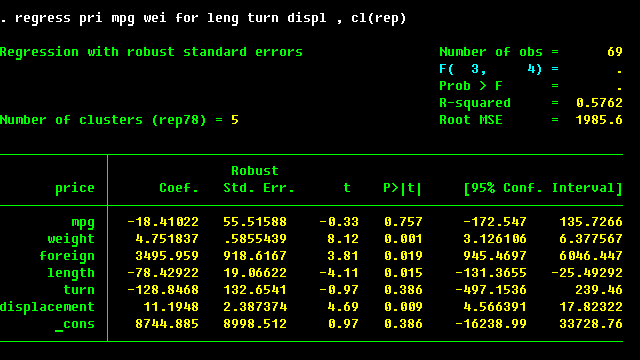
The correction for clustering is a must for survey data where the clustering reflects the multi-stage sampling design. The correction to be made then is for clustering at the very first level of sampling.