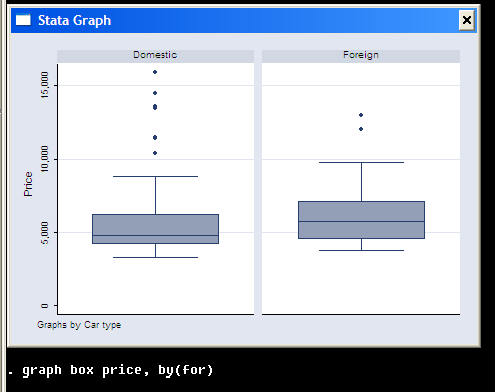
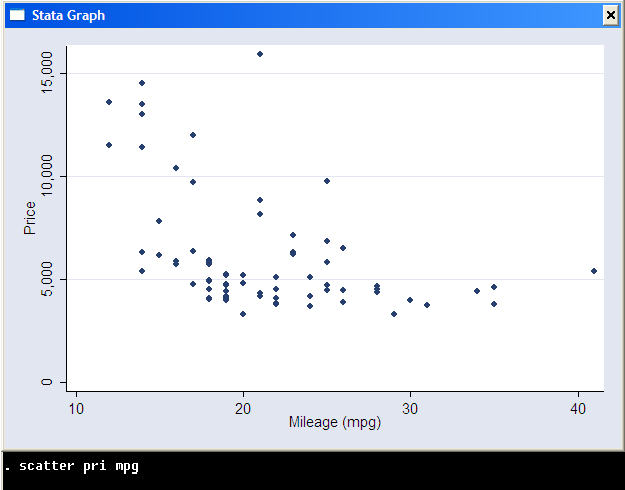
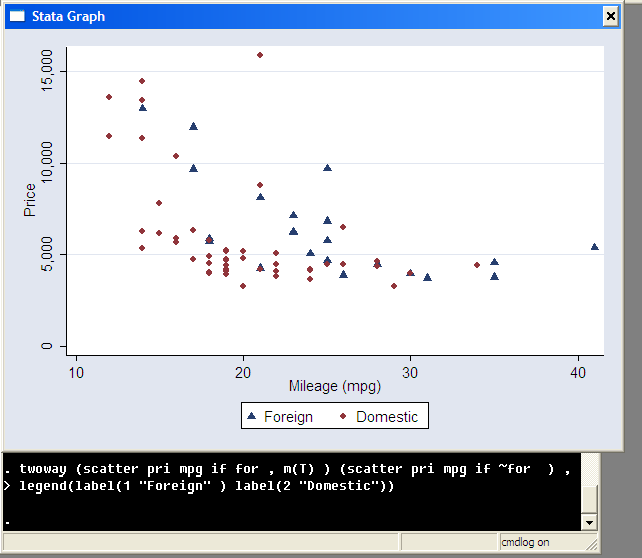
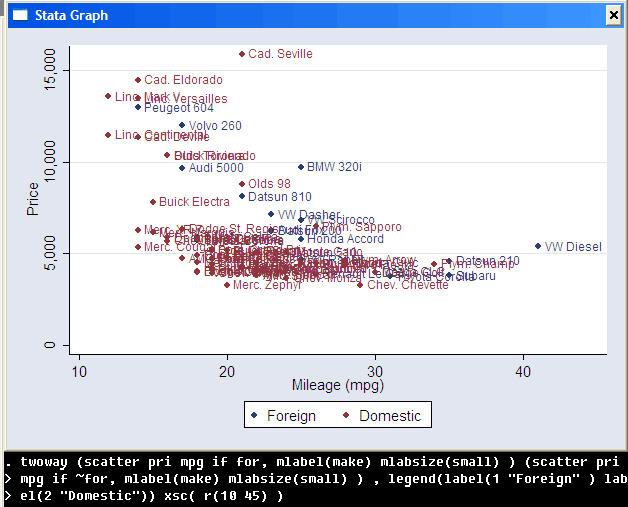
Memory issues
To see how much memory Stata uses now, and how this memory is being used, type
. memory
To change the amount of memory Stata can address, type
. set memory 40m
to request 40 Mbytes of memory.
You can usually figure out how much memory Stata may need by looking at the sizes
of the data files you are planning to work with. You can do that by typing
. ls
or better
. ls *.dta
to request a listing of dta-files.
Stata also needs some overhead for programs and temporary objects; most of the time,
adding some 15-25% is enough. Keep in mind however that when the amount of memory reaches
the physical memory of a computer (256 or 512 Mbytes on contemporary PCs), it begins swapping
the data into a temporary files on the hard disk, and the operation slows down by a factor of
about 100 to 1000. (This is not Stata's fault, this is the way virtual memory is organized
in Windows. UNIX operation is usually much smoother.)
There is also a neat trick of loading only the data you need. Recalling the general syntax
of a Stata command, you might try
use varlist if exp using filename
to load only those observations and variables you actually need. It does save you
a lot of trouble.
Another trick you might want to explore is to take a subsample of your data with
sample #, [count]
and design your analysis with this subsample. Once you have a clear plan of what you would
want to do, write a do-file (i.e., a sequence of Stata commands that can be run from
within Stata) and leave it overnight, or over weekend... or over vacation if you are
going to have any at all :).
Saving your data
To save the data, type
. save filename
You might need to specify save ..., replace option if the specified file
already exists. USE WITH CAUTION! You certainly must have your original data
in a safe place, and be sure not to ever, ever overwrite it.
See also UCLA Academic Technologies
Services Stata web site.
Converting the data from other formats
Unfortunately, Stata cannot read formats other than its own .dta or text files.
However, you can nicely convert the data between different formats by the third party utilities
such as StatTransfer or
DBMS/COPY.
It supposedly works with SAS XPT files (see
fdause), but I've never tried it.
Sometimes, the raw data comes in a plain text format, either
a fixed format (where the data from a particular column should
form a variable), or comma/tab separated format (where the data for a
single observation are listed in a line and are separated by a comma or
a tab character). Such data can be read into Stata by
. infile variables using filename, [clear]
This is also the way to export data from Excel: the data should be saved
as a plain text (comma-separated format, csv), and then they can be read
into Stata by infile or infix.
See more extensive description at
UCLA Academic Technologies Services web site.
From Stata, you can also save the data into a text file (to be exported to other
applications):
. outfile [variables using] filename, [replace]
Stata comes with a bunch of toy data sets that are often used for educational purposes. You
can retrieve the list of those data set by
. sysuse dir
and load the most popular data set on a few cars and their characteristics by
. sysuse auto
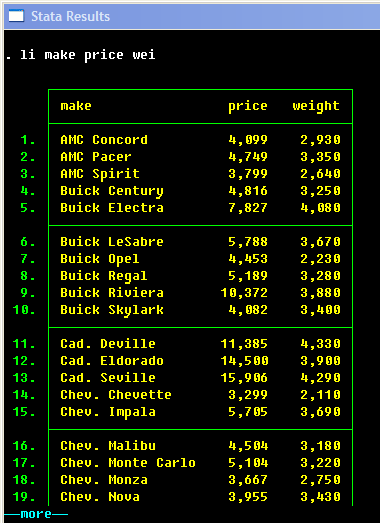
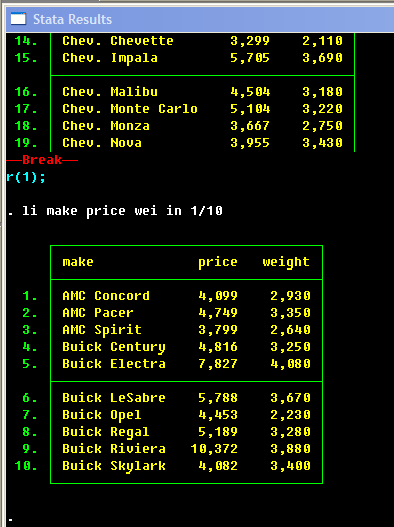
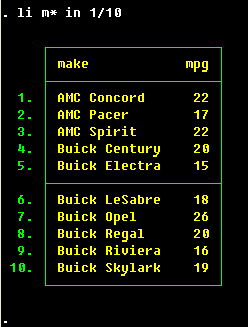
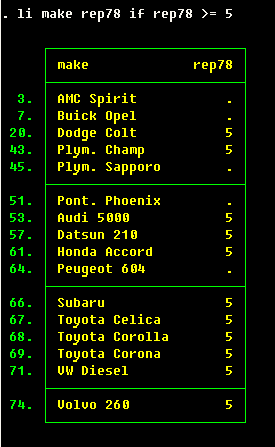
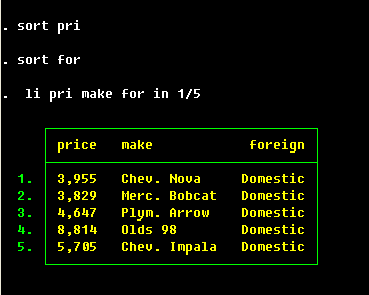
Looking at the data
Let us
. sysuse auto
to begin our session with the data. What kind of data is there? Type
. describe
to get an overall picture. In fact, it suffices to type
. d
for Stata to recognize that this is an abbreviation of describe. We shall denote the minimal
abbreviation by underlining it:
. describe
Aside: Stata colors
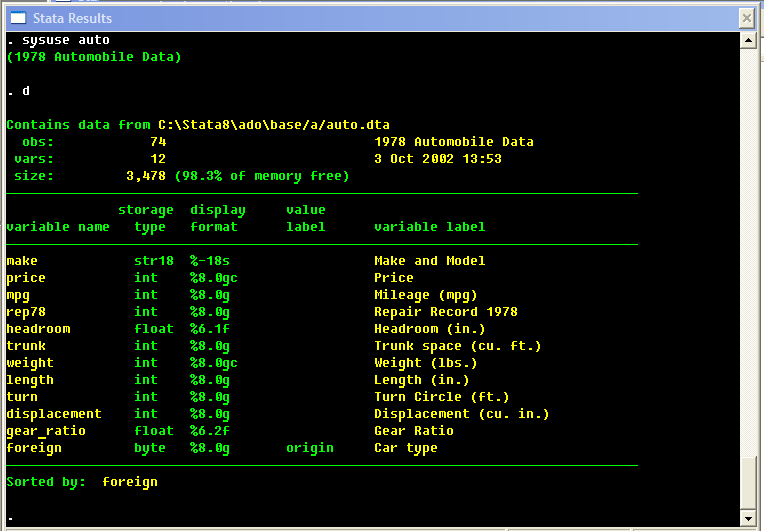 Stata uses several different colors in its output with pretty much invariable meaning.
White text shows the input Stata receives from the user (or from do-files).
Green text shows the invariable text Stata outputs. Yellow text shows the variable text
Stata outputs (e.g., variable names, numbers, file names, etc.). Red text is used for errors.
Blue text shows clickable elements: by clicking on it, you will invoke a certain Stata command,
mostly displaying a help file, or launching a browser if the highlighted element is an URL.
Stata uses several different colors in its output with pretty much invariable meaning.
White text shows the input Stata receives from the user (or from do-files).
Green text shows the invariable text Stata outputs. Yellow text shows the variable text
Stata outputs (e.g., variable names, numbers, file names, etc.). Red text is used for errors.
Blue text shows clickable elements: by clicking on it, you will invoke a certain Stata command,
mostly displaying a help file, or launching a browser if the highlighted element is an URL.
Aside: Stata guts: storage types
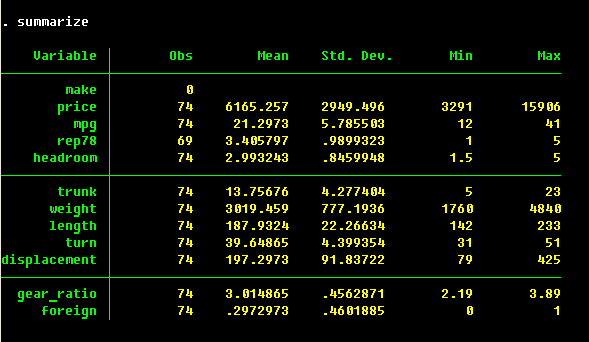
One important piece of information we can take from the above description of the data set
are the storage types of the variables in the data set. Stata distinguishes discrete,
floating point (roughly speaking, continuous) and string data types. Within each of those
types, there are also distinctions by the range of the values and accuracy. Most importantly,
for many applications the accuracy of the float type is insufficient, and it is a good
idea to use double precision in your data files and programs.
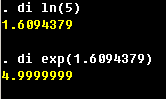 Also, the unique identifiers in the microdatasets
tend to be huge numbers, and it might be a good idea to specify those as
long. (Technically speaking, those are the data types available in C++ programming language
in which the core of Stata is written.)
See on-line help for more details.
Also, the unique identifiers in the microdatasets
tend to be huge numbers, and it might be a good idea to specify those as
long. (Technically speaking, those are the data types available in C++ programming language
in which the core of Stata is written.)
See on-line help for more details.
 on your desktop, or go to
Start -> Programs -> Stata (it may be Stata 8, Small Stata, Intercooled Stata 8, or something
else that does have a word "Stata" in it!). On UNIX machines, type
on your desktop, or go to
Start -> Programs -> Stata (it may be Stata 8, Small Stata, Intercooled Stata 8, or something
else that does have a word "Stata" in it!). On UNIX machines, type
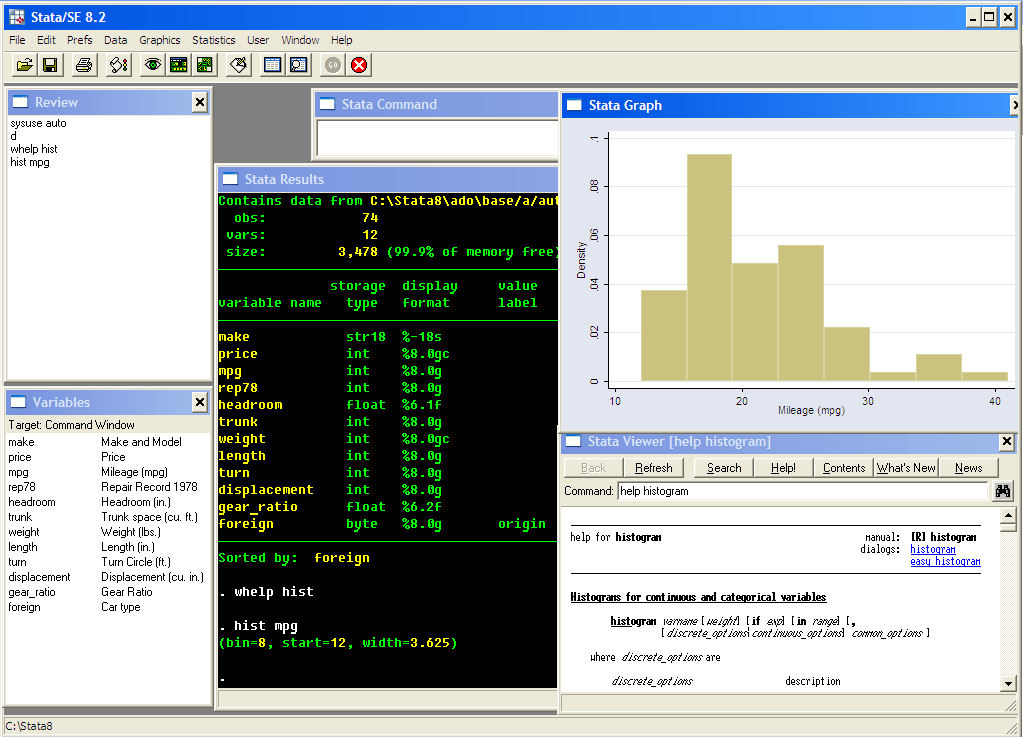
 . If there are any unsaved data, Stata will
resist exiting.
. If there are any unsaved data, Stata will
resist exiting.


 .
Looks like too much information, huh?
Try this:
.
Looks like too much information, huh?
Try this: